
论文链接:Toward Accurate Cardiac MRI Segmentation With Variational Autoencoder-Based Unsupervised Domain Adaptation
论文主要解决了心肌分割的问题,提出无监督域适应方法,将bSSFP(源域)的知识迁移到LGE(目标域)中,实现无需目标域标注的高精度分割。
关于论文的前置知识,可见KL散度、ELBO、VAE等博客。
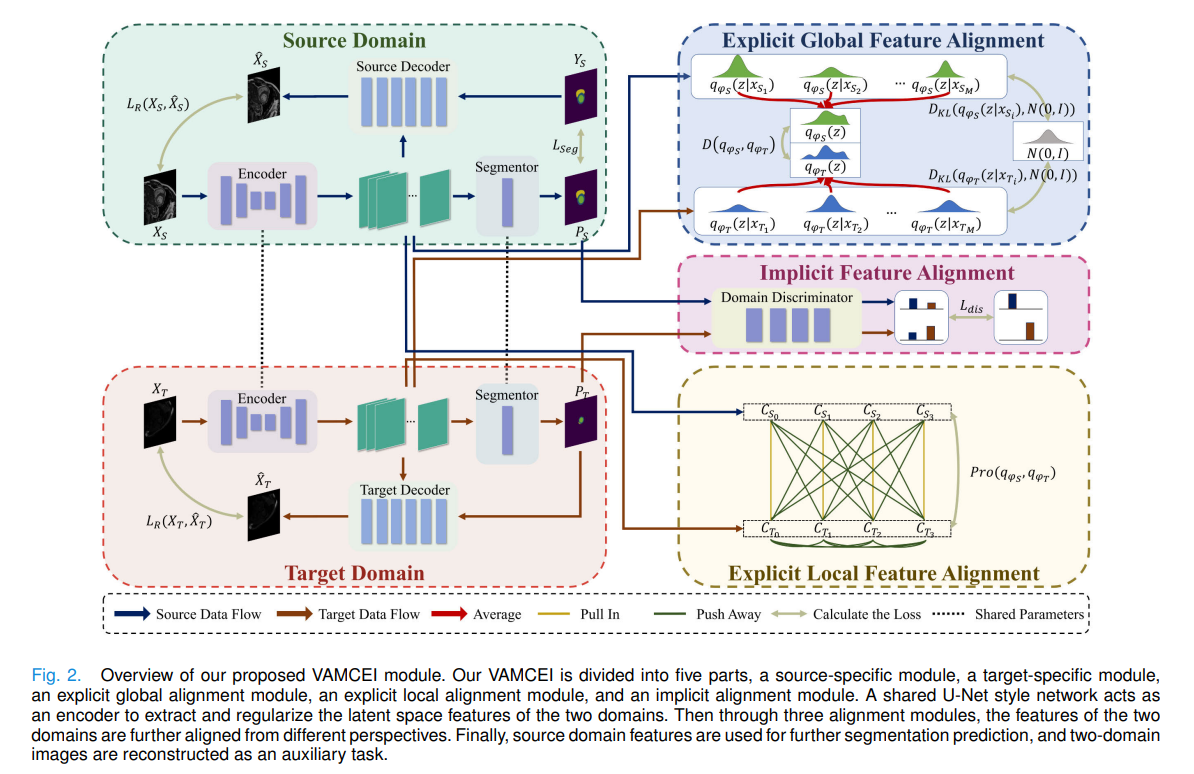
传统VAE即变分自编码器只有Encoder与Decoder两部分,论文中的VAMCEI增加了分割器部分,并且通过若干个损失函数来对齐源域和目标域的特征空间。
根据架构图,源域和目标域图像都通过UNet风格的Encoder进行特征提取(到潜在z空间),z空间通过Decoder进行重建;z空间通过分割器进行预测。根据论文的复现,有7个损失函数:
- 源域预测结果与真实掩码的分割损失
- 源域和目标域图像的重建损失
- 源域和目标域的潜在空间分布分别与标准高斯分布的 KL 散度损失(VAM正则化损失)
- 源域的整体潜在分布与目标域的整体潜在分布之间的双向 KL 散度损失(全局特征对齐损失)
- 原型对比损失(局部特征对齐损失)
- 源域和目标域上生成器与判别器的对抗损失(隐式特征对齐损失)
论文复现代码见:cardiac_uda_vamcei
接下来重点解析论文中的关键数学推导,包括:
- 变分自编码器(VAE)的目标函数
- 显式全局特征对齐(KL散度推导)
- 显式局部特征对齐(原型对比损失)
- 隐式特征对齐(对抗损失)
- 多阶段框架中的知识蒸馏损失
以下逐一详细解释:
关键公式与推导
1. VAE基础:变分下界(公式1)
VAE的核心目标是最大化观测数据
变量说明:
:输入图像(心脏MRI) :分割标签(LV/RV/Myo) :潜在变量 :编码器输出的后验分布(近似真实后验 ) :先验分布(标准正态 ) :解码器重建的图像分布 :分割器预测的标签分布
三项分解:
-
KL散度项:
强制潜在空间
服从标准正态分布(正则化)。
具体计算(公式2,两正态分布的KL散度有公式):其中
为 batch 大小, 为潜在空间维度, 为第 个样本第 维的均值和方差。 -
重建项:
最大化重建图像
的似然,对应二值交叉熵损失(公式3): -
分割项:
分割预测损失(公式4):
结合交叉熵和 Dice 损失处理类别不平衡。
2. 显式全局特征对齐(公式5-8)
核心问题: 源域和目标域潜在空间分布不一致,导致域偏移。
解决方案: 最小化两域潜在分布的 KL 散度。
-
双向 KL 散度(公式5):
传统方法用 L2 距离,本文创新性地采用对称 KL 散度更准确度量分布差异。
-
小批量近似(公式6):
-
高斯近似(公式7):
-
独立维度分解(公式8):
其中
为源域第 个样本第 维的均值和方差, 为目标域对应值。
关键在于将复杂的多维积分转化为可计算的求和。
3. 显式局部特征对齐(公式9-10)
目标: 对齐同类特征,分离异类特征(跨域)。
举例来说,是为了对齐源域和目标域中心肌 Myo 的特征,分离源域心肌 Myo 与目标域右心室 RV 的特征。
-
类别原型计算(公式9):
其中
为第 个样本第 像素的特征向量, 为指示函数(像素属于类别 时为 1)。 -
原型对比损失(公式10):
其中
为余弦相似度, 为温度系数。
4. 隐式特征对齐(公式11-12)
通过输出空间域判别器实现。
-
判别器损失(公式11):
目标:区分源域/目标域分割图
。 -
生成器(编码器)损失(公式12):
编码器试图"欺骗"判别器,使目标域分割图
被误判为源域,实现隐式特征对齐。
5. 多阶段框架蒸馏(公式16)
目标: 融合互补模型知识,避免语义错误。
-
知识蒸馏损失(公式16):
其中:
:教师模型平均概率(Target VAMCEI + Source VAMCEI) :学生模型预测概率 :蒸馏温度(软化概率分布) :类别数
物理意义: 最小化学生与教师输出的 KL 散度,传递"暗知识"(dark knowledge)。